Transfer Learning, Covariant Learning and Parallel Transport
Appears in collection : Statistics and Machine Learning at Paris-Saclay (2023 Edition)
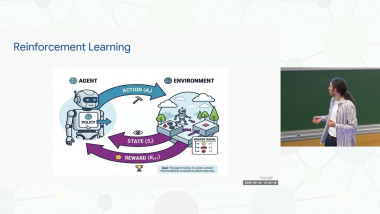
Transfer learning has become increasingly important in recent years, particularly because learning a new model for each task can be much more costly in terms of training examples than adapting a model learned for another task. The standard approach in neural networks is to reuse the learned representation in the first layers and to adapt the decision function performed by the last layers. In this talk, we will revisit transfer learning. A dual algorithm of the standard approach, which adapts the representation while keeping the decision function, will be presented, as well as an algorithm for the early classification of time series. This will allow us to question the notion of bias in transfer learning as well as the cost of information and to ask ourselves which a priori assumptions are necessary to obtain guarantees on transfer learning. We will note that reasoning by analogy and online learning are instances of transfer learning, and we will see how the notions of parallel transport and covariant physics can provide useful conceptual tools to address transfer learning.