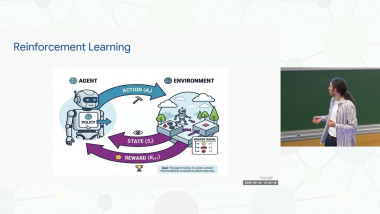
Reinforcement learning (RL) studies the problem of learning how to optimally controlling a dynamical and stochastic environment. Unlike in supervised learning, a RL agent does not receive a direct supervision on which actions to take in order to maximize the longterm reward, and it needs to learn from the samples collected through direct interaction with the environment. RL algorithms combined with deep learning tools recently achieved impressive results in a variety of problems ranging from recommendation systems to computer games, often reaching human-competitive performance (e.g., in the Go game). In this course, we will review the mathematical foundations of RL and the most popular algorithmic strategies. In particular, we will build around the model of Markov decision processes (MDPs) to formalize the agent-environment interaction and ground RL algorithms into popular dynamic programming algorithms, such as value and policy iteration. We will study how such algorithms can be made online, incremental and how to integrate approximation techniques from the deep learning literature. Finally, we will discuss the problem of the exploration-exploitation dilemma in the simpler bandit scenario as well as in the full RL case. Across the course, we will try to identify the main current limitations of RL algorithms and the main open questions in the field.
Theoretical part
- Introduction to reinforcement learning (recent advances and current limitations)
- How to model a RL problem: Markov decision processes (MDPs)
- How to solve an MDP: Dynamic programming methods (value and policy iteration)
- How to solve an MDP from direct interaction: RL algorithms (Monte-Carlo, temporal difference, SARSA, Q-learning)
- How to solve an MDP with approximation (aka deep RL): value-based (e.g., DQN) and policy gradient methods (e.g., Reinforce, TRPO)
- How to efficiently explore an MDP: from bandit to RL
Practical part
- Simple example of value iteration and Q-learning
- More advanced example with policy gradient
- Simple bandit example for exploration
- More advanced example for exploration in RL