Multi-armed bandits and beyond
Apparaît dans la collection : Theoretical Computer Science Spring School: Machine Learning / Ecole de Printemps d'Informatique Théorique : Apprentissage Automatique
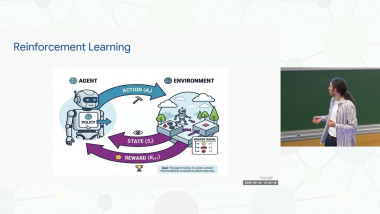
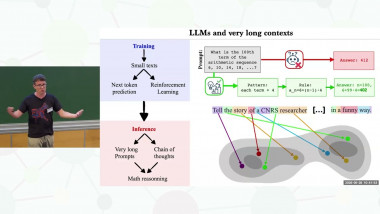
In this tutorial I will discuss recent advances in theory of multi-armed bandits and reinforcement learning, in particular the upper confidence bound (UCB) and Thompson Sampling (TS) techniques for algorithm design and analysis.