Collection Imaging and machine learning
Organisateur(s)
Date(s)
14/05/2024
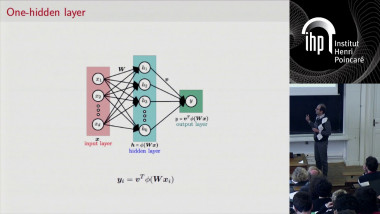
Multimodal representation learning for text and image has been extensively studied in recent years. Currently, one of the most popular tasks in this field is Visual Question Answering (VQA). I will introduce this complex multimodal task, which aims at answering a question about an image. To solve this problem, visual and textual deep nets models are required and, high level interactions between these two modalities have to be carefully designed into the model in order to provide the right answer. This projection from the unimodal spaces to a multimodal one is supposed to extract and model the relevant correlations between the two spaces. Besides, the model must have the ability to understand the full scene, focus its attention on the relevant visual regions and discard the useless information regarding the question.
De Guillermo Sapiro
De Guillaume Obozinski
De José Lezama
De Bertrand Thirion
De Christoph Brune
De Lorenzo Rosasco
De Remco Duits
De Patrick Pérez
De Matthieu Cord
De Mahdi Soltanolkotabi
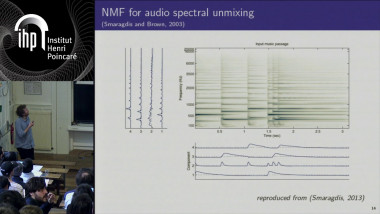
De Cédric Févotte
De Stéphane Mallat
De Marta Betcke
De Francis Bach
De Stéphane Mallat
De Giuseppe Savaré
De Philippe Laurençot
De Dejan Slepčev
De Juan Camilo Arosemena Serrato
De Amine Marrakchi
De Shirly Geffen
De Francesca Arici